Disclaimer rápido: todo lo que vas a leer viene de la documentación oficial de Atlassian. Nosotros solo pusimos nuestro toque, nuestras analogías raras y un par de emojis 😉.
Imagina que tu base de datos es tu cafecito diario. Ahora imagina que tienes 4 millones de esos cafecitos y necesitas moverlos todos a otro servidor sin que nadie se quede sin café. 😅 Pues eso fue exactamente lo que Atlassian hizo.
El gran reto
Mover una base de datos ya es complicado. Pero Atlassian tenía que mover millones. Sí, leíste bien: 4 millones de bases de datos de Jira, repartidas en 3,000 instancias de PostgreSQL en 13 regiones de AWS. Cada base tiene TODO: issues, proyectos, flujos de trabajo, campos personalizados… básicamente la mochila de un estudiante muy organizado.
Y lo hicieron sin que los usuarios notaran ni un parpadeo.
Arquitectura de Jira: una base por cliente
La mayoría de las empresas apilan varios clientes en una sola base. Atlassian decidió hacer todo lo contrario: una base de datos por cliente. ¿Por qué?
- Máxima seguridad: imposible que los datos de uno se mezclen con otro.
- Escalabilidad: cada base crece según su propio ritmo.
- Control total: fácil de mover, equilibrar y mantener en orden.
Parece loco, pero funciona… hasta que tienes millones de bases.
Aurora vs RDS: el cambio que lo hizo posible
Antes usaban RDS. Pero RDS es como un auto de un solo pasajero: solo un escritor activo y un lector, nada más. Aurora cambió las reglas:
- 💡 Doble instancia: puedes usar escritor + lectores al mismo tiempo.
- ⚡ Autoescalado: hasta 15 lectores adicionales en horas pico.
- 🕒 SLA mejorado: de 99.95% a 99.99% uptime (menos de una hora de caída al año).
- 💸 Downsizing inteligente: servidores más pequeños, misma potencia.
En resumen: más rapidez, más confiabilidad, menos gasto.
Diseño de la migración
¿Cómo mover millones de bases sin que nadie se entere? Atlassian lo resolvió así:
- Read replica: clonar la base original y sincronizar datos en Aurora mientras la base original sigue funcionando.
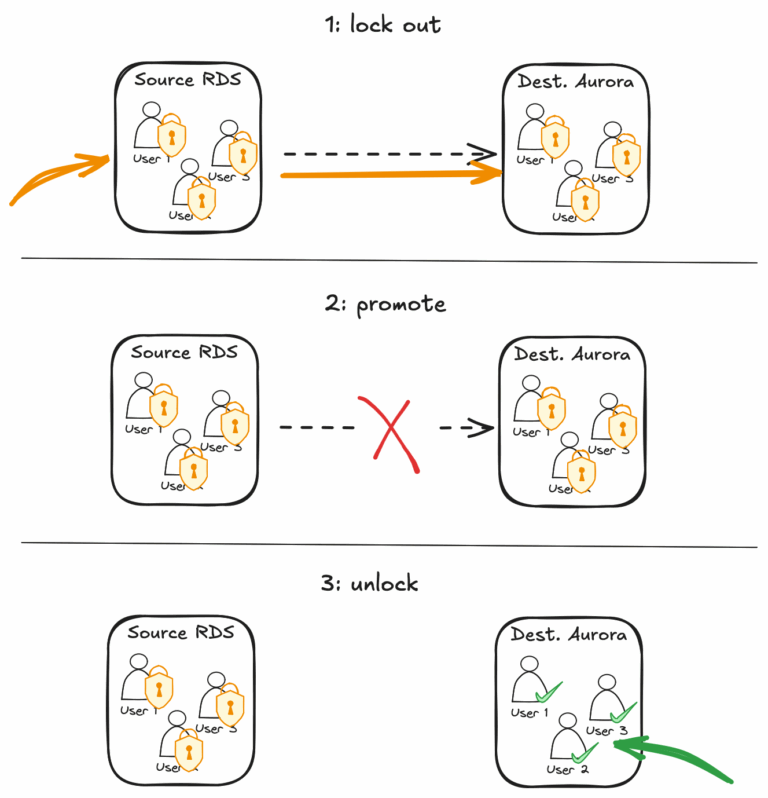
- Cutover coordinado: bloquear usuarios, promover la réplica a Aurora, actualizar endpoints y desbloquear usuarios.
- Orquestación con AWS Step Functions: un workflow que verifica cada paso y puede retroceder si algo falla.
- Feature flags: cambiar endpoints al instante en lugar de esperar a que las aplicaciones se den cuenta solas.
Resultado: cada corte duraba menos de 3 minutos, incluso para las instancias más grandes. ⏱️
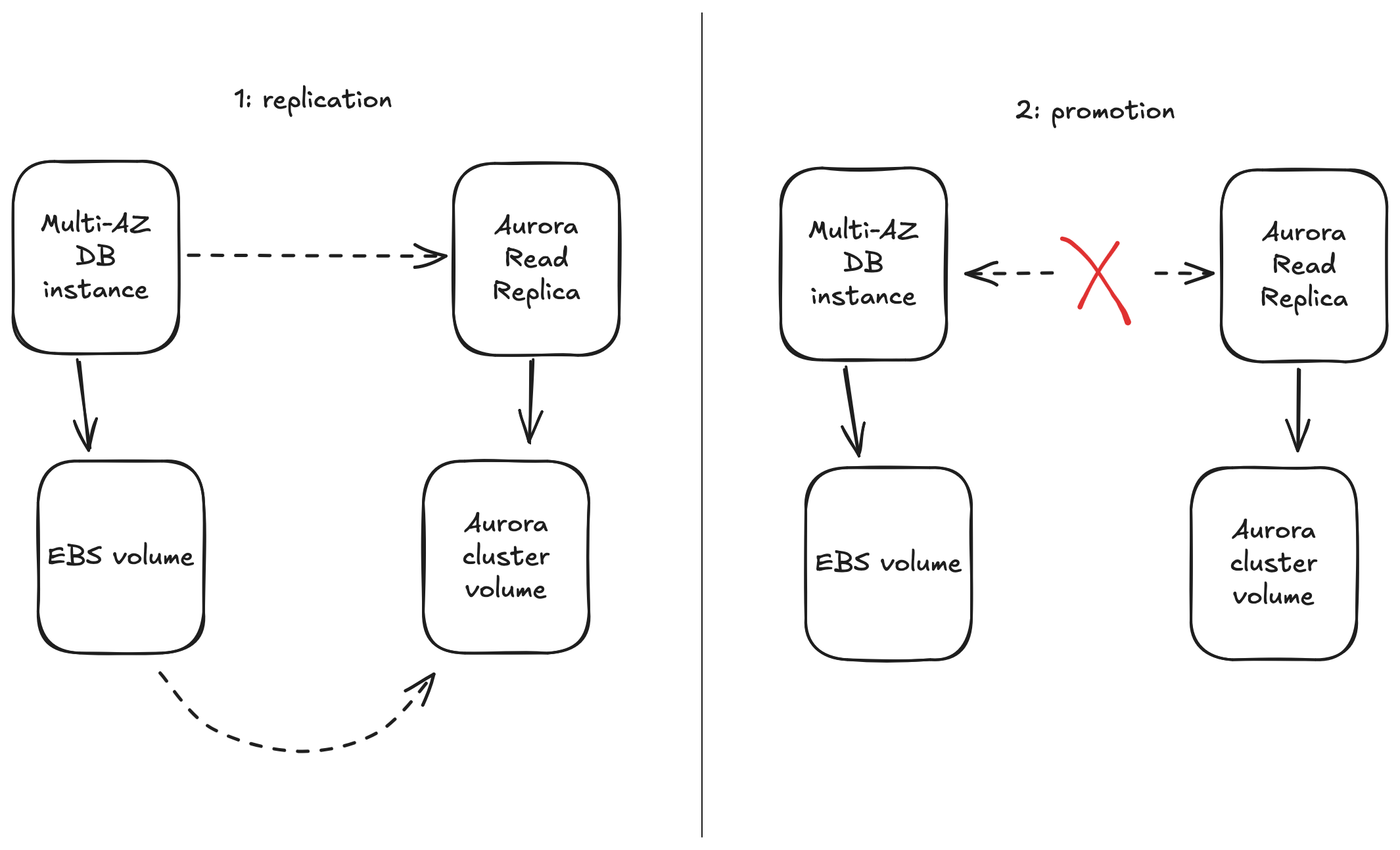
Obstáculos iniciales
Todo parecía perfecto… hasta que AWS avisó que algunas réplicas no arrancaban. La razón: demasiados archivos en cada instancia. Aurora tenía un límite de tiempo al iniciar y la enumeración de millones de archivos estaba tardando más de lo permitido. 😬
El problema de los archivos: cuando “mucho es demasiado”
Cada base de Jira tiene miles de tablas, índices y secuencias. Cada uno de esos objetos = al menos un archivo en disco. Con 4,000 bases por cluster, estamos hablando de 20 millones de archivos por cluster. 😱
Aurora intentaba contarlos todos al arrancar… y se quedaba atrapada en el conteo como si intentaras contar granos de arena uno por uno mientras la playa se mueve. Resultado: timeout en el startup.
AWS dijo: “Chicos, tienen que reducir archivos… o reducir bases por cluster”. Obvio, no podían eliminar tablas, así que solo quedaba draining.
La solución: Draining y Daisy Chain 🚰🌼
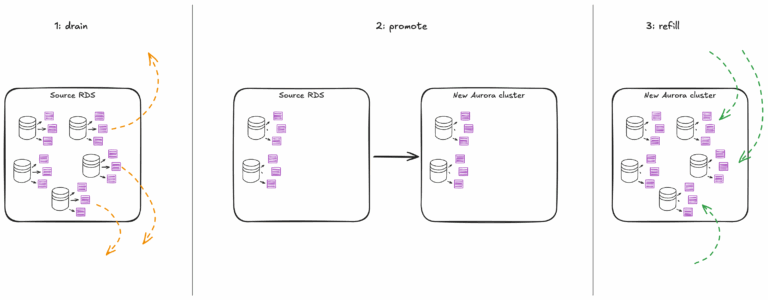
Draining = vaciar la instancia: mover algunas bases a otra mientras la instancia original se convierte en Aurora.
El plan:
- Drain: mover las bases más pequeñas primero, las que menos usan datos y tráfico. Así la migración es rápida y segura.
- Convert: la instancia ya con menos bases se convierte en Aurora usando la estrategia de read replica + cutover.
- Refill: usar la nueva Aurora como destino para otras bases que siguen siendo migradas.
Esto creó un efecto “Daisy Chain”: una instancia después de otra, todas en fila, sin saturar infraestructura ni romper nada.
Escalando como locos
Para que esto funcionara, tuvieron que controlar:
- Source concurrency: cuántas migraciones salían al mismo tiempo de un RDS.
- Destination concurrency: cuántas bases podían entrar al Aurora simultáneamente.
Si dejaban que Aurora recibiera demasiado al mismo tiempo, se saturaba. Así que optimizaron la cantidad de clusters y la velocidad de migración como un DJ ajustando el volumen en una fiesta: suficiente para bailar, pero sin romper el equipo. 🎧
El resultado:
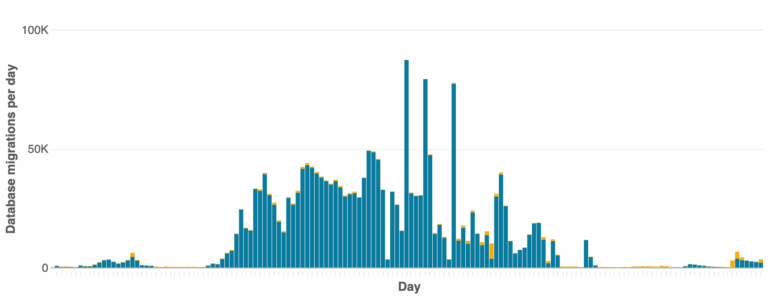
- Promedio diario: 38,000 migraciones
- Pico máximo: 90,000 migraciones
Todo mientras los usuarios seguían sin notar nada.
Los resultados finales: triple instancia, doble eficiencia 💪
Al final, se sorprendieron muchos: Aurora tenía casi el triple de clusters que RDS. Pero no es desperdicio:
- Cada cluster es más pequeño, más barato, pero igual de potente gracias a escritor + lectores.
- Escala automáticamente en horas pico y se reduce en horas bajas.
- SLA mejorado: menos downtime y mayor confiabilidad.
En números:
- 2403 RDS convertidos a Aurora
- 2.6 millones de bases migradas
- 27.4 mil millones de archivos procesados
Aurora y Atlassian lograron el equilibrio perfecto: menos gasto, más rendimiento y usuarios felices. 🎯
El broche de oro
Este proyecto no solo fue una migración; fue un manual de supervivencia y eficiencia a escala. Y un agradecimiento gigante a AWS, que lidiaron con millones de archivos sin que nadie se muriera en el intento.
Si alguna vez pensaste que mover bases de datos es aburrido, ahora sabes que puede ser una épica mezcla de estrategia, matemáticas y magia tecnológica. 🪄
References: