
¡Hey, qué tal! Hoy te voy a contar (como si estuviéramos platicando con un café de por medio) lo que pasó con Cloudflare el 18 de noviembre de 2025, una de esas mañanas donde, de repente, una buena parte de Internet decidió tomarse un descanso no planeado. Spoiler: no fue un ataque malvado ni el fin del mundo tecnológico… pero sí algo bastante embarrado en la ingeniería.
El susto matutino: “¿Qué se rompió?”
Imagina que te levantas temprano, abres tu app favorita (ChatGPT, X, Canva, lo que sea) y plop: error 500. No eres el único; decenas de sitios se cayeron. Fue como si Cloudflare —ese gigante que muchos ni vemos pero está detrás de millones de páginas— hubiera estornudado, y medio internet se resfrió.
Desde su propio blog, Cloudflare confirmó que a las 11:20 UTC comenzó el caos. Pero, ojo: aclararon que no era un ciberataque ni un hacker cabrón rompiendo todo (aunque al principio muchos sospecharon eso).
¿Qué demonios falló? Una base de datos y un “archivo de características” tocados de más
Aquí viene lo técnico, pero no te asustes: lo explico en cristiano.
Cloudflare tiene un sistema para manejar bots (esas visitas automáticas, a veces buenas, a veces malas). Para eso usa un “archivo de características” (“feature file”), que es como un listado con rasgos que su modelo de bots lee para decidir si algo es bot o humano.
Ese archivo se genera automáticamente cada pocos minutos, usando consultas a una base de datos ClickHouse. Pero el 18 de noviembre hicieron un cambio en los permisos de esa base de datos. Esa modificación causó que la consulta que genera el archivo doble filas (sí, mucha duplicación) en el resultado. El archivo creció más del doble de lo esperado.
El problema es que el software que lee ese archivo tiene un límite rígido: esperaba como máximo ~200 “features”, pero el archivo duplicado lo dejó por encima de ese límite. Resultado: el sistema se puso en pánico (“panic” para los devs) y empezó a mandar errores 5xx.
La montaña rusa de errores
Lo más raro fue que no fue un desastre instantáneo y permanente, sino una especie de “sube y baja”: en algunos momentos el sistema se recuperaba, en otros volvía a fallar. ¿Por qué? Porque cada 5 minutos había una nueva versión de ese archivo (buena o mala) que se propagaba por toda la red de Cloudflare.
Como no sabían todavía que era un bug interno, inicialmente pensaron que podría ser un superataque DDoS — y no los culpo, cuando tienes picos raros de tráfico cualquiera se espanta.
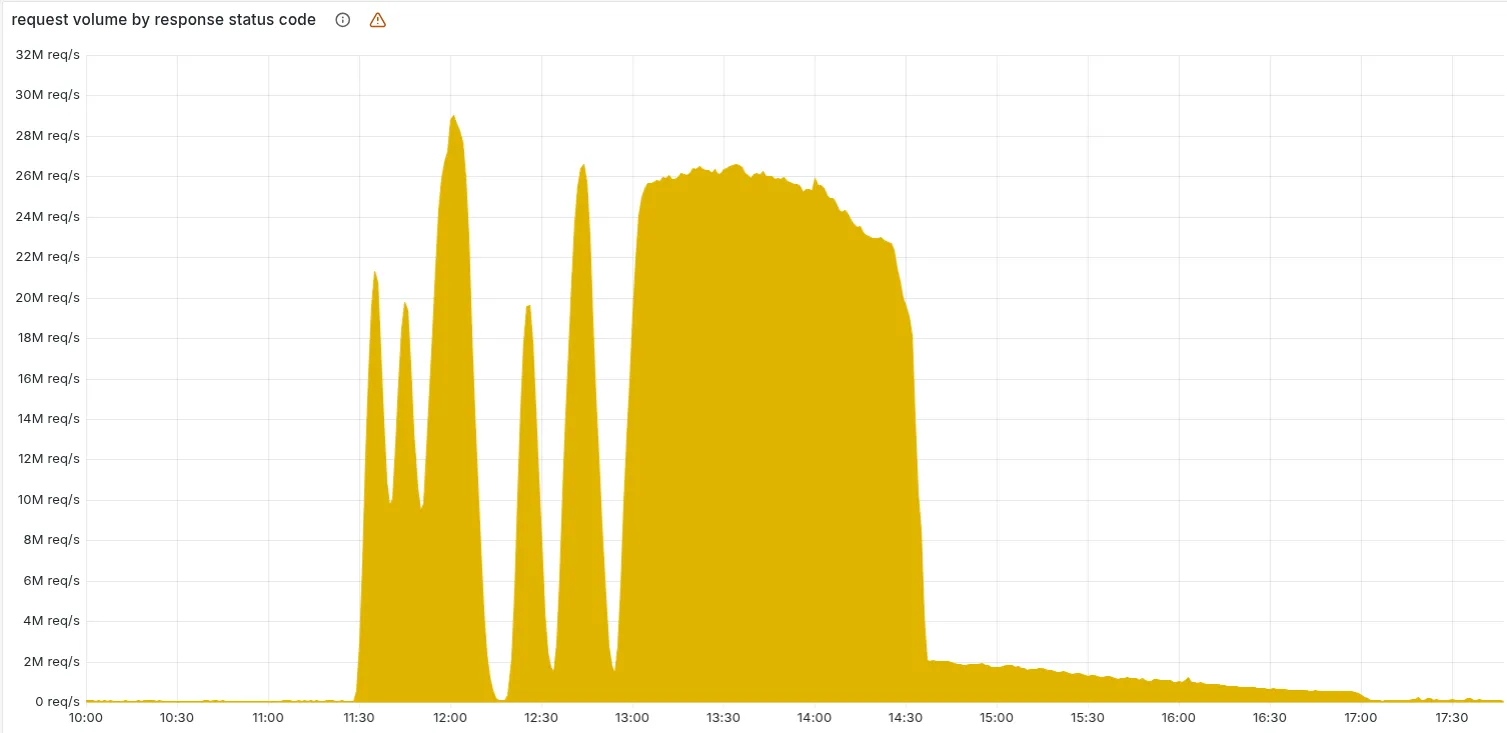
Finalmente, a eso de las 14:30 UTC lograron detener las versiones malas del archivo, pusieron una versión antigua (y buena) a mano, y reiniciaron los proxys principales para que todo volviera a cargar bien.
Y para ir cerrando el asunto, para las 17:06 UTC ya todos los servicios estaban de regreso.
¿Qué se vio afectado?
No fue sólo un par de sitios raros: se cayó un buen pedazo de la red.
Algunos de los servicios impactados incluyen:
- CDN y seguridad core de Cloudflare (mucho tráfico 5xx).
- Turnstile (el sistema para verificar identidades / retos) dejó de cargar bien.
- Workers KV (el almacén de datos distribuido) tuvo muchos errores 5xx.
- El Panel (Dashboard) dejó de permitir iniciar sesión para muchos usuarios, porque Turnstile fallaba.
- Cloudflare Access (servicio de autenticación) también falló: muchos usuarios no pudieron autenticarse.
- Hubo latencia extra en su CDN: la CPU de algunas máquinas estaba muy ocupada con diagnósticos y depuración.
Así que no era un “es sólo un sitio”, fue una cascada bastante grave.
¿Y Cloudflare qué prometió para que no vuelva a pasar?
Bueno, después del caos siempre toca prometer mejoras, ¿no? Estos son algunos de los planes que mencionaron para evitar que algo así se repita:
- Endurecer la parte de ingestión de archivos de configuración: van a validar más el tamaño, la estructura, y otras cosas del “feature file” antes de propagarlo como locos.
- Interruptores globales (“kill switches”) para características: para poder desactivar algo rápidamente si se rompe.
- Evitar que los core dumps (volcados de memoria) o los reportes de errores se traguen sus recursos: básicamente, que el desmadre de un error no ponga de rodillas a otras partes del sistema.
- Revisar todos los módulos principales del proxy para los modos de falla: que tengan más “plan B” cuando algo no va como debería.
Además, su CEO Matthew Prince pidió disculpas sinceras: sí, meter la pata así está mal, y se sienten responsables por lo que afectó a un montón de clientes y usuarios.
¿Qué dijo la prensa y los nerds?
- The Register no pudo evitar el chiste: “Cloudflare se rompió a sí mismo con una mala consulta de base de datos”. The Register
- También reportaron que Cloudflare, al principio, pensó que esto era un mega-DDoS. The Register
- En Reddit (sí, por supuesto la gente opinó): varios devs dijeron algo así como “metieron un
.unwrap()en producción sobre un error… y bueno, todo explotó”. Reddit - Otros comentarios mencionan que es extraño que no tuvieran validaciones antes de propagar el archivo duplicado; suenan justo, ¿no? Reddit
¿Por qué debería importarte (aparte de que fue un show BRUTAL)?
- Nos recuerda que incluso los grandes fallan: Cloudflare no es invencible.
- Es un llamado de atención para los negocios: depender muchísimo de un solo proveedor tiene sus riesgos. Si tú eres una app o un sitio, podría valer la pena pensar en redundancias.
- También es una lección técnica buenísima para quienes trabajan en infra o devops: validar archivos de configuración, tener límites, kill switches, monitoreo… todo eso no es lujo, es necesidad.
Reflexión liviana: la ironía del guardián que se duerme
¿No es algo irónico? La empresa que protege sitios, que sirve como muro ante bots y ataques, terminó tumbando parte de la red por un bug en su sistema de protección de bots. Es como si el guardaespaldas se desmayara por proteger.
Se podría decir que Cloudflare se dio un “respiro” no planeado, y el internet lo sintió. Pero lo bueno es: aprendieron, pidieron perdón, y ya están trabajando para que no se repita.
Ok, ¿y ahora qué?
- Cloudflare se equivocó de forma épica, pero no fue por un ataque malicioso. Lo causó un cambio interno mal calibrado.
- El sistema colapsó porque un archivo creció más allá de lo previsto, y no había defensas para eso.
- La recuperación tomó horas, pero al final regresaron a la normalidad (al menos para la mayoría).
- Van a poner más validaciones, apagar funciones rápido si algo no va bien, y revisar bien sus procesos: una promesa grande.
Y bueno, como diría un amigo: “ese susto sí se sintió”, pero parece que aprendieron la lección. Esperemos que la próxima no tengamos que ver otro “Internet 500 Internal Error Party”.
Nos vemos pronto para la próxima charla tecnológica (ojalá con menos apagonazos).





