Este post es una traducción del artículo original titulado "DELETEs are difficult", escrito por Radim Marek, publicado en su blog Not So Boring SQL. En este artículo, Marek profundiza en los desafíos y las implicaciones que conllevan las operaciones DELETE en bases de datos, y cómo pueden afectar el rendimiento, la gestión de bloat y las estrategias para manejarlas de manera eficiente.
Tu base de datos está funcionando bien, hasta que un simple DELETE la pone de rodillas. ¿Qué salió mal? Mientras tendemos a centrarnos en optimizar operaciones como SELECT e INSERT, a menudo pasamos por alto las complejidades ocultas de DELETE. Sin embargo, eliminar datos innecesarios es igual de crítico. Los datos obsoletos o irrelevantes pueden sobrecargar tu base de datos, degradar su rendimiento y convertir el mantenimiento en una pesadilla. Peor aún, retener ciertos tipos de datos sin una justificación válida podría incluso generar problemas de cumplimiento de ley o certificación.
A primera vista, el comando DELETE parece sencillo. Incluso la documentación de PostgreSQL proporciona ejemplos simples como:
DELETE FROM films WHERE kind <> 'Musical';
DELETE FROM films;
Estas consultas pueden funcionar sin problemas en tu máquina de desarrollo, donde solo existen unos pocos cientos de registros. Pero, ¿qué sucede cuando intentas ejecutar un DELETE similar en producción, donde los conjuntos de datos son órdenes de magnitud mayores?
En este artículo, descubriremos por qué las operaciones DELETE exigen una consideración cuidadosa y exploraremos cómo manejarlas de manera efectiva.
¿Qué sucede realmente cuando eliminas datos?
A primera vista, una consulta DELETE podría parecer sencilla. Sin embargo, una vez que se ejecuta, ocurre una serie de pasos complejos:
- Identificación de filas: Similar a una operación SELECT, la consulta identifica las filas visibles para la transacción actual (considerando MVCC) y verifica los bloqueos.
- Adquisición de bloqueos: La base de datos adquiere bloqueos exclusivos a nivel de fila para prevenir otras operaciones en las filas objetivo.
- Disparador BEFORE DELETE: Si se define un disparador BEFORE DELETE, se ejecuta en este punto.
- Marcar filas como eliminadas: En lugar de ser eliminadas físicamente, las filas se marcan como eliminadas en la transacción actual, haciéndolas invisibles para futuras consultas (dependiendo del aislamiento de la transacción). Si la tabla tiene objetos grandes, también se involucra la tabla TOAST.
- Actualización de índices: Las entradas de índice correspondientes también se marcan para eliminación (si aplica).
- Acciones en cascada: Se realizan operaciones en cascada, como ON DELETE CASCADE, en tablas relacionadas.
- Disparador AFTER DELETE: Si se define un disparador AFTER DELETE, se ejecuta.
- Registro en el WAL (Write-Ahead Log): Los cambios se registran primero en el WAL a nivel de fila, seguido por las actualizaciones de los índices.
Solo cuando se confirma la transacción, estos cambios se vuelven permanentes y visibles para las transacciones que comienzan posteriormente. Sin embargo, incluso en este punto, los datos no se eliminan físicamente. Así es como se crea el bloat.
Hasta que el proceso de autovacuum o una operación manual de VACUUM recupere el espacio, los datos "eliminados" permanecen. Estos datos residuales contribuyen al bloat, lo que puede degradar el rendimiento de las consultas con el tiempo.
¿Son los DELETE realmente la operación más difícil para nuestra base de datos?
La respuesta: probablemente sí. Aunque las UPDATE son cercanas en complejidad, generalmente están diseñadas de manera que las hacen menos desafiantes:
- Las UPDATE suelen modificar solo un número limitado de columnas, reduciendo las actualizaciones de índices necesarias.
- No todas las UPDATE desencadenan una actualización completa de la fila (COLD), donde la fila antigua se marca como eliminada y se crea una nueva fila. Con un diseño cuidadoso de tablas y consultas, puedes minimizar estos casos. Las actualizaciones HOT (Heap-Only Tuple), por ejemplo, son más fáciles de lograr con columnas de longitud fija.
- A diferencia de las DELETE, las UPDATE no activan acciones en cascada, solo disparadores explícitamente definidos.
Y entonces llega el AUTOVACUUM
Cuando el autovacuum se activa (y realmente quieres que lo haga) —generalmente debido a umbrales para el número de tuplas muertas o cambios en la tabla— se requiere una cantidad significativa de trabajo para limpiarlas. Este es un desglose paso a paso:
- El proceso comienza escaneando la tabla. Aunque no siempre es un escaneo completo, el autovacuum verifica el mapa de visibilidad y las páginas donde podrían existir tuplas muertas.
- Cada tupla se verifica para asegurarse de que ya no sea visible para ninguna transacción activa o pendiente.
- Las tuplas muertas que pasan la verificación de visibilidad se eliminan físicamente de la tabla.
- Las entradas de índice correspondientes a las tuplas eliminadas se actualizan.
- El espacio ahora vacío se marca para su reutilización en futuras operaciones INSERT o UPDATE.
- Se actualizan las estadísticas de la tabla para reflejar el estado actual, ayudando al planificador de consultas a tomar mejores decisiones.
- Los cambios, incluidas las eliminaciones de tuplas y actualizaciones de índices, se registran en el WAL para durabilidad y replicación.
- Si la tabla tiene datos TOAST (objetos grandes), también se procesan las tablas TOAST asociadas.
- El mapa de visibilidad se actualiza para marcar las páginas limpiadas como completamente visibles nuevamente.
- El autovacuum reinicia los umbrales para determinar cuándo debe ocurrir la próxima operación de vacuum.
Este proceso continúa hasta alcanzar el límite de costo de vacuum configurado (en el caso de autovacuum), momento en el cual se pausa o detiene. Aunque el autovacuum ayuda a mantener tu base de datos en buen estado, queda claro que recuperar tuplas muertas no es una tarea menor, lo que resalta por qué las operaciones DELETE pueden tener efectos duraderos en el rendimiento de la base de datos.
Aunque el AUTOVACUUM pueda parecer una mala noticia, sin él tu base de datos se llenaría rápidamente de tuplas muertas, lo que resultaría en un rendimiento degradado, consultas más lentas, mayor uso de almacenamiento e incluso el riesgo de errores por falta de espacio en disco, ya que el espacio no utilizado no podría recuperarse.
Consideraciones adicionales
Lo que parece una simple operación DELETE ya implica una cantidad sorprendente de trabajo, pero la complejidad no termina ahí. Las operaciones DELETE pueden presentar desafíos adicionales, especialmente cuando entran en juego la replicación, la contención de recursos o el tamaño de la operación.
En entornos con replicación hacia servidores en espera activa o réplicas, los DELETE se vuelven más sensibles al tiempo. La transacción no puede completarse hasta que los registros correspondientes del WAL (Write-Ahead Log) se hayan escrito en disco en el servidor en espera. Este es un requisito fundamental para mantener la consistencia de los datos en configuraciones de alta disponibilidad, donde típicamente hay al menos un servidor en espera involucrado. Además, si el servidor en espera está atendiendo operaciones de lectura activamente, debe procesar los DELETE antes de confirmar los cambios, lo que puede introducir más demoras.
El tamaño de la operación DELETE también juega un papel crítico. Los DELETE pequeños, como eliminar una sola fila, tienden a tener un impacto mínimo. Sin embargo, a medida que aumenta el tamaño de la operación, también crece el volumen de registros WAL generados. Los DELETE grandes pueden sobrecargar el sistema, ralentizando las transacciones y poniendo bajo presión el proceso de replicación. Los servidores en espera deben trabajar más para procesar el flujo entrante del WAL, lo que puede convertirse en un cuello de botella si su capacidad de procesamiento es insuficiente.
La contención de recursos añade otra capa de complejidad, especialmente en DELETE grandes. Generar registros WAL, manejar cargas de trabajo transaccionales regulares y ejecutar procesos en segundo plano pueden empujar colectivamente al sistema hacia la saturación de I/O. Esto genera competencia por los recursos de CPU y memoria, lo que ralentiza las operaciones en general.
Por último, una vez que los datos se marcan para eliminación, el proceso de autovacuum debe intervenir eventualmente para eliminarlos físicamente. Esto introduce su propio conjunto de desafíos, ya que el autovacuum enfrenta la misma contención de recursos y demandas de I/O, lo que agrava aún más el impacto general de la operación DELETE inicial.
Los soft-deletes no son la solución
Los soft-deletes pueden parecer una forma sencilla de evitar las complejidades de las operaciones DELETE tradicionales. Al fin y al cabo, actualizar un campo como deleted_at es un proceso directo y poco probable que desencadene una actualización COLD. Sin embargo, los soft-deletes no son un mecanismo real para eliminar datos y vienen con su propio conjunto de complicaciones.
Aunque los soft-deletes ofrecen una forma sencilla de implementar una funcionalidad de “deshacer”, plantean serias preguntas sobre la consistencia de los datos. Por ejemplo, ¿solo marcas como eliminada la entidad principal, o también aplicas el mismo estado a todos los registros relacionados en tablas referenciadas? No aplicar esta cascada correctamente puede dejar tu base de datos en un estado inconsistente, dificultando el mantenimiento de la integridad de los datos.
Además, los soft-deletes requieren un ajuste en la lógica de tu aplicación. Cada consulta debe incluir filtros adecuados para excluir las filas “eliminadas”, lo que puede complicar el diseño de las consultas y aumentar el riesgo de errores. Un filtro omitido podría exponer datos que ya no deberían ser visibles, lo que podría derivar en problemas de seguridad o lógica empresarial.
Finalmente, los soft-deletes no resuelven el problema; simplemente lo aplazan. Los datos siguen en tu base de datos, ocupando espacio de almacenamiento y contribuyendo potencialmente a la degradación del rendimiento con el tiempo. Tarde o temprano, tendrás que abordar la eliminación real de estos datos, llevándote de nuevo a los mismos desafíos que presentan las operaciones DELETE.
Al momento de escribir este artículo, solo podemos especular sobre cuánto cambiará el soporte para claves primarias temporales y restricciones UNIQUE en PostgreSQL 18 el panorama futuro. Sin embargo, dada la complejidad de esta característica, no apostaría demasiado por ello todavía.
El batching es la respuesta
Dar a PostgreSQL tiempo para procesar y ponerse al día con cambios a gran escala es crucial al lidiar con operaciones como DELETE. El problema central aquí es la duración y magnitud de la transacción. Cuanto más corta sea la transacción y menos cambios se realicen, mejor podrá PostgreSQL gestionar y conciliar esos cambios. Este principio es universal en todas las operaciones de bases de datos y subraya la importancia de minimizar el impacto de las transacciones individuales.
Aunque puedes optimizar ciertos aspectos, como la identificación de filas (usando índices, agrupamiento u otras técnicas similares), los conjuntos de datos más grandes requieren un enfoque más estratégico: batching. Por ejemplo, eliminar 1 millón de filas en una sola transacción es el ejemplo clásico de lo que no se debe hacer. En su lugar, dividir la operación en lotes más pequeños, como eliminar 10,000 filas en 100 iteraciones, es mucho más efectivo.
¿Será este método más rápido que realizar un DELETE masivo de una sola vez? Probablemente no, especialmente si incluyes un tiempo de espera entre lotes para permitir que PostgreSQL maneje otras cargas de trabajo. Sin embargo, la compensación vale la pena. Al utilizar batching, le das a PostgreSQL más margen para gestionar los cambios sin saturar las cargas de trabajo transaccionales regulares, a menos que hayas programado un tiempo de mantenimiento dedicado para la operación.
Cómo realizar DELETEs por lotes
La forma más sencilla de realizar DELETEs por lotes es utilizar una subconsulta o una Expresión de Tabla Común (CTE) para limitar el número de filas afectadas en cada iteración. Por ejemplo, en lugar de ejecutar un DELETE masivo como este:
DELETE FROM films WHERE kind <> 'Musical';Puedes dividir la operación en bloques más pequeños. Usando una consulta como la siguiente, puedes eliminar filas repetidamente en lotes manejables (por ejemplo, utilizando \watch en psql para automatizar las iteraciones):
DELETE FROM films
WHERE ctid IN (
SELECT ctid FROM films
WHERE kind <> 'Musical'
LIMIT 250
);El uso de ctid en este ejemplo se basa en una columna de sistema de PostgreSQL que proporciona un identificador único para cada fila. Al seleccionar valores de ctid en la subconsulta, puedes limitar la cantidad de filas afectadas en cada iteración. Este enfoque es más eficiente que usar LIMIT directamente en la consulta principal, ya que evita la necesidad de volver a escanear la tabla en cada lote.
Si no te sientes cómodo usando ctid (tema que merecería un artículo por sí solo), puedes emplear una búsqueda regular por clave primaria y agregar un LIMIT.
Planificación para Autovacuum
El uso de lotes por sí solo no resuelve directamente el problema de que el autovacuum se ponga al día con los cambios. Es necesario planificarlo por separado. Ajustar la configuración de autovacuum o ejecutar manualmente comandos como VACUUM y VACUUM ANALYZE puede ayudar a manejar el bloat creado durante el proceso de DELETE.
Sin embargo, deshabilitar el autovacuum rara vez es recomendable, a menos que se haya planificado cuidadosamente el mantenimiento manual durante las operaciones por lotes. Omitir este paso puede dejar un bloat que afecte el rendimiento y que requiera aún más esfuerzo para resolver más adelante.
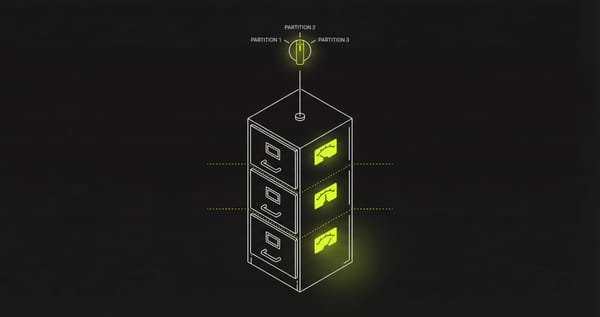
Eliminar rangos completos de datos con particiones
Los datos que están naturalmente segmentados, como por el tiempo de creación, son excelentes candidatos para ser eliminados mediante particiones. La partición permite evitar completamente las operaciones DELETE, simplemente eliminando (DROP) o truncando (TRUNCATE) las particiones relevantes. Este enfoque es mucho más eficiente, ya que elimina la sobrecarga de escanear, bloquear y marcar filas como eliminadas, resolviendo de raíz el problema del bloat.
Aunque la partición agrega cierta complejidad al diseño del esquema y a la planificación de consultas, puede ofrecer importantes beneficios de rendimiento para cargas de trabajo con muchas operaciones de DELETE, especialmente si se combina con una gestión automatizada de particiones.
Conclusión
Las operaciones DELETE suelen ser una fuente de sorpresas desagradables, no solo por afectar el rendimiento y generar bloat, sino porque pueden tener efectos inesperados en momentos críticos. Para manejarlas de manera eficaz, enfócate en estrategias como el uso de lotes, el monitoreo de autovacuum o el aprovechamiento de particiones para grandes conjuntos de datos. Al considerar las operaciones DELETE desde el diseño del esquema, puedes mantener una base de datos eficiente, reducir problemas de mantenimiento y asegurar que siga funcionando sin problemas a medida que crecen tus datos.