Recuerdo como si fuera ayer: trabajaba en esa empresa de chatbots donde cada día generaban millones de registros. Llevaban años en el mercado, así que las tablas de conversaciones eran monstruos con historial de años. Hacer un simple UPDATE o DELETE era una novela: LIMIT 10k, iterando hasta el cansancio mientras el café se enfriaba.
El post de Last9 sobre Database Partitioning me pegó directo al hígado. "¡Esto nos habría salvado la vida!" pensé. No es teoría bonita; es el antídoto para tablas que se convierten en elefantes. Vamos a desglosarlo como si estuviéramos en el lunch, con código que sí funciona.
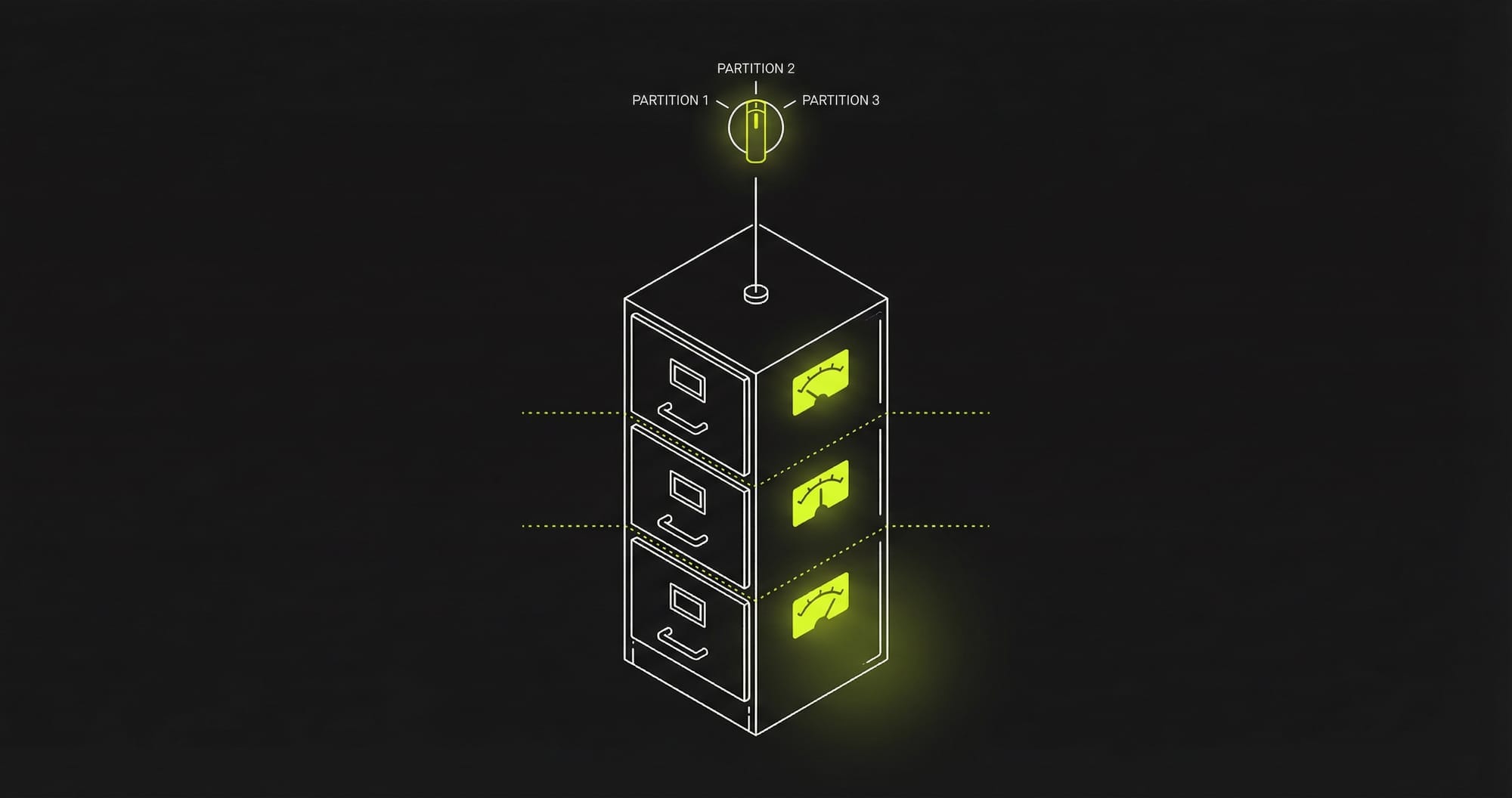
Partitioning: dividir para conquistar (sin mover servidores)
En cristiano: Tomas tu tabla gigante y la rompes en pedacitos manejables dentro del mismo servidor. Postgres/MySQL hace la magia: tus queries solo tocan la partición correcta. Tu app no se entera de nada.
No es sharding (eso ya es otro nivel de dolor). Partitioning = mismo servidor, mejor perf, menos drama.
Mi dolor pasado: conversations con 500M+ rows. Un DELETE WHERE created_at < '2024-01-01' tomaba horas y lockeaba todo. Con partitioning: desenchufas la partición vieja en segundos.
Range Partitioning: tu nuevo mejor amigo
Para chatbots, logs, orders —todo lo que tiene timestamps.
-- Tabla madre particionada
CREATE TABLE conversations (
id BIGSERIAL,
user_id INT,
message TEXT,
created_at TIMESTAMPTZ NOT NULL
) PARTITION BY RANGE (created_at);
-- Particiones mensuales (cron las crea)
CREATE TABLE conv_202501 PARTITION OF conversations
FOR VALUES FROM ('2025-01-01') TO ('2025-02-01');Magia pura:
-- Esto SOLO toca conv_202501
SELECT * FROM conversations
WHERE created_at BETWEEN '2025-01-15' AND '2025-01-20';Eliminar histórico (el sueño):
ALTER TABLE conversations DETACH PARTITION conv_202401;
DROP TABLE conv_202401; -- ¡Segundos!¿Ves la diferencia? Antes: horas de DELETE LIMIT 10k. Ahora: detach y ¡Ka-chow!.
Mi odisea real: del caos al "por qué no lo hicimos antes"
Nuestras queries típicas eran un chiste de terror:
-- ANTES: Full scan 500M rows (minutos)
UPDATE conversations SET status = 'archived'
WHERE created_at < NOW() - INTERVAL '1 year' LIMIT 10000;
-- x50k iteraciones = pesadillaCon partitioning:
-- Segundos, cero locks
ALTER TABLE conversations DETACH PARTITION conv_202401;Ganancias reales:
VACUUMpor partición = 10x más rápido- Queries por fecha tocan solo 1/12 del dataset
- Mantenimiento sin downtime
EXPLAINdeja de dar pesadillas
Otros sabores (elige tu veneno)
List Partitioning (por tenants/regiones):
CREATE TABLE events (
id BIGSERIAL, region TEXT NOT NULL, payload JSONB
) PARTITION BY LIST (region);
CREATE TABLE events_mx PARTITION OF events
FOR VALUES IN ('mx-nte', 'mx-cdmx');Hash Partitioning (user_id pareja):
CREATE TABLE sessions (
id BIGSERIAL, user_id INT NOT NULL, data JSONB
) PARTITION BY HASH (user_id);¿Cuándo meterle mano? (no te emociones)
SÍ, YA:
- Tablas >50M rows con filtros fecha/region
DELETEhistórico >5minVACUUM FULLte paraliza- Sequential scans en
EXPLAIN
NO, PARA:
- Tablas chicas (<5M)
- Queries sin partition key (peor que nada)
- Write-heavy (sharding territory)
Regla de oro: 80%+ de queries deben usar tu partition key.
Mi sentencia final
Last9 lo clava: partitioning antes que sharding. DDL simple, app intacta, resuelve 80% de dramas de tablas gordas.
En mi empresa habríamos ahorrado meses de sufrimiento y miles (en dinero) en infra.
Tu misión 2026: Audit queries → partition key → migra. Tu DBA futuro te mandará birria.
Nos vemos en el próximo EXPLAIN que no te quite el sueño. ¿Qué tabla monstruosa tienes gritando por partitioning?